
로딩 중이에요... 🐣
[코담]
웹개발·실전 프로젝트·AI까지, 파이썬·장고의 모든것을 담아낸 강의와 개발 노트
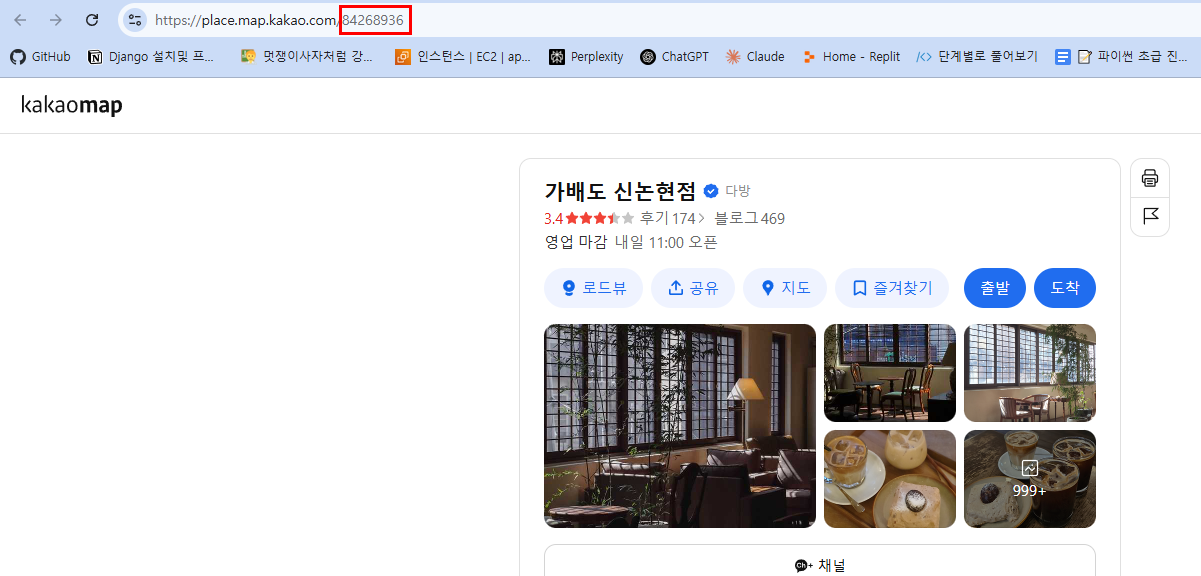
01 카카오맵에서 리뷰와 기타정보가져오기 | ✅ 저자: 이유정(박사)
place.map.kakao.com 기존 크롤러에서 place id 찾기
순서:
- 상세보기로 이동
- 매장정보 버튼 클릭
- 매장정보와 태크 크로링
여기서 마지막 숫자 348276052가 Place ID입니다.
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.ui import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
def scrap_kakao_place_info(place_id):
"""
카카오맵의 장소 페이지에서 해시태그 및 편의시설 정보를 수집합니다.
Args:
place_id (str): 카카오맵 장소 고유 ID (예: '84268936')
Returns:
List[str]: 태그와 편의시설 정보를 담은 문자열 리스트
"""
# options는 선택사항으로 없어도 됨
# Headless 모드 (브라우저 창 없이 실행) 창이 살짝 열리다 닫힌다.
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu') # (Windows에서 권장)
options.add_argument('--no-sandbox') # (Linux에서 권장)
url = f"https://place.map.kakao.com/{place_id}"
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
driver.get(url)
wait = WebDriverWait(driver, 10)
# 2. "펼치기" 버튼 클릭하여 숨겨진 태그 영역 표시
try:
fold_button = wait.until(ec.element_to_be_clickable((By.CLASS_NAME, "btn_fold2")))
driver.execute_script("arguments[0].click();", fold_button)
time.sleep(2) # 클릭 후 렌더링 대기
except Exception as e:
print("펼치기 버튼 없음 또는 클릭 실패:", e)
# 3. 해시태그 섹션이 로드될 때까지 대기
try:
wait.until(ec.presence_of_element_located((By.CLASS_NAME, "unit_hashtag")))
except:
print("태그가 로딩되지 않음")
# 4. HTML 소스 추출 및 파싱
html_content = driver.page_source
driver.quit()
soup = BeautifulSoup(html_content, "html.parser")
texts = []
# 5. 해시태그 수집 (class="unit_hashtag" → class="link_detail")
try:
tag_section = soup.find("div", class_="unit_hashtag")
if tag_section:
tag_links = tag_section.find_all("a", class_="link_detail")
texts += [tag.text.strip().lstrip("#") for tag in tag_links]
else:
print("[디버깅] unit_hashtag 블록 없음")
except Exception as e:
print("태그 추출 실패:", e)
# 6. 편의시설 수집 (예: 주차, 와이파이 등)
list_facility = soup.find("ul", class_="list_facilities")
if list_facility:
facility_tags = list_facility.find_all("span", class_="txt_svc")
texts += [tag.text for tag in facility_tags]
# 7. 불필요한 공백 제거 후 결과 반환
return ["".join(t.split()) for t in texts]
# from selenium_crawler.kakao_place_scrap import scrap_kakao_place_info
# 가배도 신논현점
# print(scrap_kakao_place_info("84268936"))
# 결과:
# ['강남역카페', '신논현카페', '티라미수', '가배도', '카페', '빈티지분위기', '애견동반카페', '제로페이', '반려견동반', '포장가능', '와이파이']
jupyter
from selenium_crawler.kakao_place_scrap import scrap_kakao_place_info
# 가배도 신논현점
print(scrap_kakao_place_info("84268936"))
결과:
['강남역카페', '신논현카페', '티라미수', '가배도', '카페', '빈티지분위기', '애견동반카페', '제로페이', '반려견동반', '포장가능', '와이파이']